Google Launches Flex and Priority Inference Tiers for Gemini API
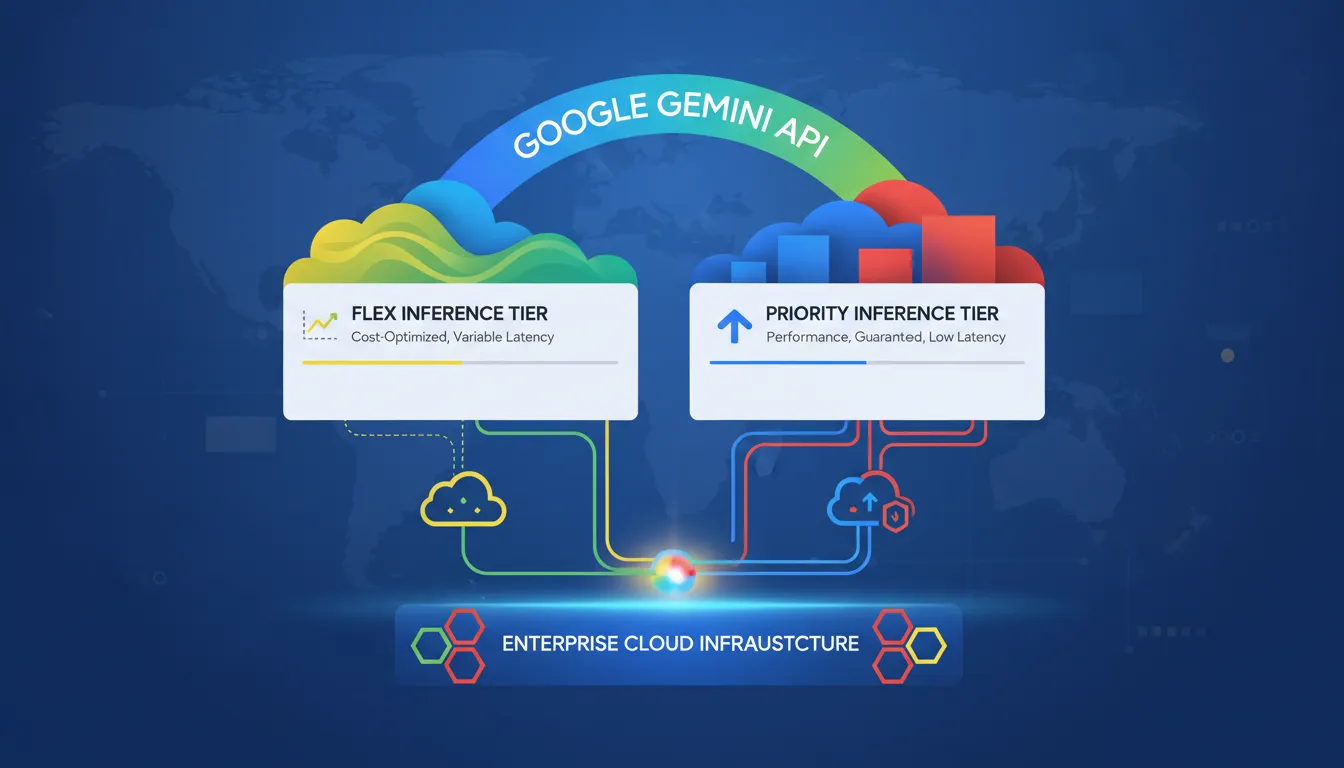
Google today introduced two new pricing tiers for the Gemini API: Flex Inference and Priority Inference. The new options give developers and enterprises significantly more control over balancing cost and reliability for AI workloads.
Flex Inference offers a 50% discount compared to standard API pricing. It leverages opportunistic, off-peak compute capacity and is designed for latency-tolerant workloads such as background CRM updates, large-scale research simulations, and agentic workflows. Requests may be preempted if standard traffic spikes, and users are responsible for implementing client-side retry logic.
Priority Inference is the premium tier, priced 75 to 100% above standard rates. It guarantees the lowest latency and highest reliability. Priority traffic is never shed, and in cases where capacity limits are reached, requests automatically fall back to the standard tier. This tier is ideal for live customer chatbots, real-time fraud detection, and business-critical copilots. Priority Inference requires Tier 2 or Tier 3 paid projects.
For CIOs and engineering teams already using the Gemini API in production, this is a practical improvement: no more overpaying on every API call just to ensure reliability where it actually matters.
📬 Likte du denne?
AI-nyheter for ledere. Kuratert av en CIO som bygger det selv. Daglig i innboksen.


